https://dl.acm.org/citation.cfm?id=2648589
摘要
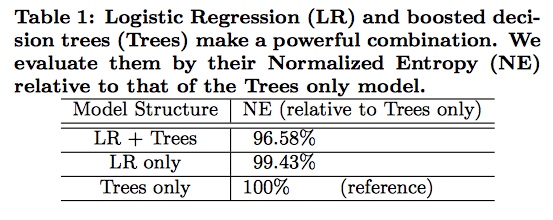
在线广告允许广告商只投标和支付可测量的用户响应,比如广告的点击。所以,点击预测系统时大多数广告系统的中心。有超过7.5亿的日活用户和超过一百万的活跃广告商,预测Facebook广告点击是一项有挑战的机器学习任务。这篇论文介绍一个决策树加逻辑回归的组合模型,使用组合模型的效果比单独使用模型的效果提升3%,这会对整体系统的表现的提升产生重大影响。作者探索了一些基础参数怎么影响系统的最终预测表现。不出意外的是,最重要的事情是拥有正确的特征:捕获到的用户和广告的历史信息支配着其他类型的特征。一旦我们有了正确的特征和正确的模型(决策树加逻辑回归),其他的因素就影响很小(虽然小的改进在规模上很重要)。选择对数据新鲜度,学习率模式,和数据采样的最佳处理能够轻微的改变模型,但远不如一开始就选择高价值的特征或选择正确的模型。
介绍
这篇论文的目的就是分享用真实世界的数据,并且具有鲁棒性和适应性的实验中得到的见解。
Facebook由于其特殊性,不能使用搜索记录进行广告推荐,而是基于对用户的定位,所以可展示广告的量也更多。Facebook为此建立的级联分类器。这篇文章专注于级联分类器的最后一个阶段点击预测模型,就是这个模型对最终的候选广告集的广告进行预测是否会被点击。1
2*级联分类器*
级联是基于几个分类器的串联的集合学习的特定情况,使用从给定分类器的输出收集的所有信息作为级联中的下一个分类器的附加信息。与投票或堆叠合奏(多专家系统)不同,级联是多阶段的。
实验
主要介绍实验计划。
实验数据:2013年第4季度任意1周的离线训练数据,与线上数据相似。分为训练集和测试集,并且使用它们模拟在线训练和预测的流数据。论文中实验使用的都是相同的训练/测试数据。
评估指标:
Normalized Entropy (NE),NE定义为: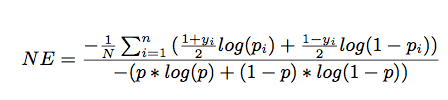
其中yi属于{-1,+1},p为经验点击通过率CTR(即广告实际点击次数除以广告展示量)。NE在计算相关的信息增益时是至关重要的。上面是逻辑回归的损失函数,也就是交叉熵。下面是个常数,所以越小值,模型越好。
Calibration (刻度标度):评价估计CTR和经验CTR的比率。即预期点击次数与实际观察点击次数的比率。越接近1模型效果越好。
预测模型结构
评估不同的概率线性分类器和不同的在线学习算法。
混合模型结构:提升决策树和概率稀疏线性分类器的串联。
学习算法是用的是Stochastic Gradient Descent(SGD),或者Bayesian online learning scheme for probit regression(BOPR)都可以。但是最终选择的是SGD,原因是资源消耗要小一些。
SGD和BOPR都可以针对单个样本进行训练,所以他们可以做成流式的学习器(stream learner)。
决策树特征转换
对于一个样本,针对每一颗树得到一个类别型特征。该特征取值为样本在树中落入的叶节点的编号。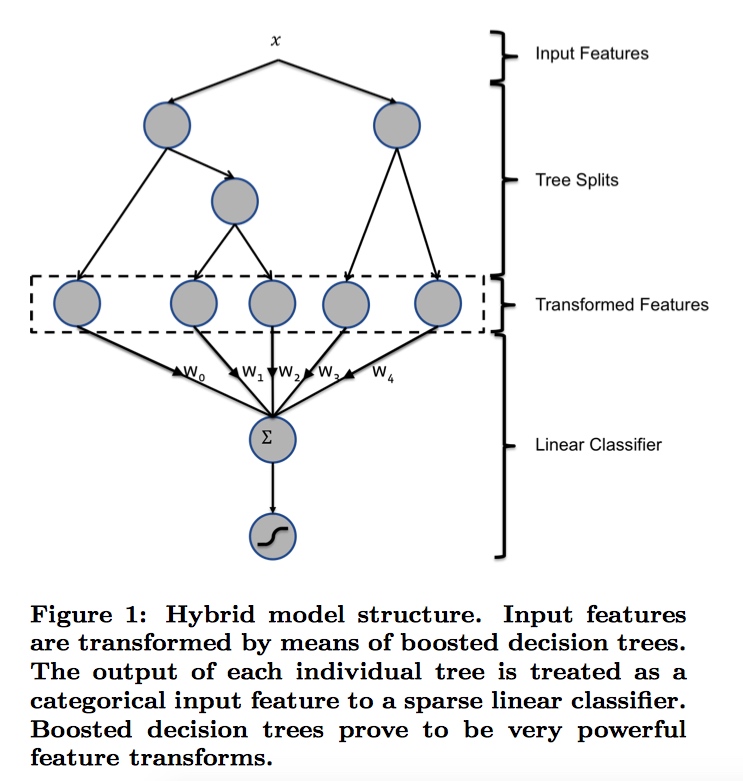
上图中的提升决策树包含两棵子树,第一棵树包含3个叶节点,第二棵树包含2个叶节点。输入样本x,在两棵树种分别落入叶子节点2和叶子节点1。那么特征转换就得到特征向量[0 1 0 1 0]。也就是说,把叶节点编号进行one-hot编码。
直观的理解这种特征变化:
- 看做是一种有监督的特征编码。把实值的vector转化为紧凑的二值的vector。
- 从根节点到叶节点的一条路径,表示的是在特征上的一个特定的规则。所以,叶节点的编号代表了这种规则。表征了样本中的信息,而且进行了非线性的组合变换。
- 最后再对叶节点编号组合,相当于学习这些规则的权重。
Data freshness
一天的数据作为训练集,其后的一天活几天作为测试数据。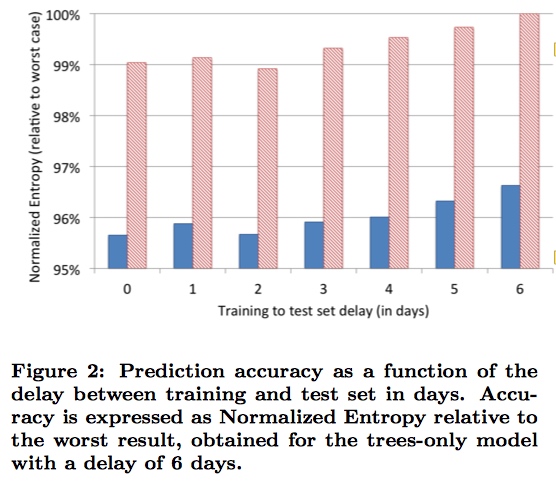
可以发现随着天数的增加,data freshness也变得越来越差,模型的性能也越来越差。
一种做法是说每天都重新训练。即使是mini-batch来训练,也会非常耗时。提升树的训练时间受很多因素的影响,比如:样本数量、树深度、树数量、叶子节点个数等。为了加快速度,可以在多CPU上通过并行化来实现。
我们可以:
- 提升树可以一天或者几天来训练一次。
- LR可以实现在线学习,几乎是实时训练。
LR线性分类器
针对Logistic Regression进行在线增量训练。也就是说只要用户点击了广告,生成了新的样本,就进行增量训练。
Facebook针对SGD-based online learning研究了5中学习速率的设置方式。
- 前三种使得不同的参数有不同的学习速率
- 后两种对于所有的参数都是用相同的学习速率
实验结果显示Per-coordinate learning rate效果最好:
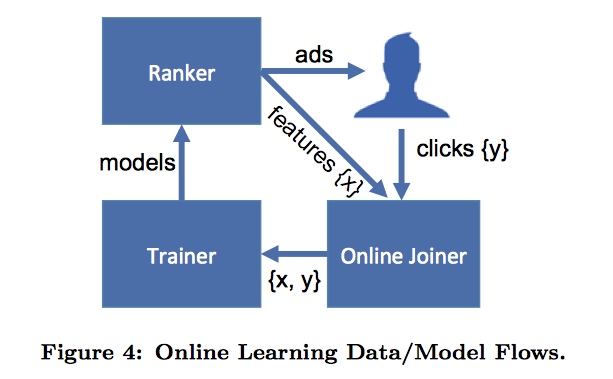
线上模型架构
最关键的步骤就是把labels(click/no-click)和训练输入(ad impressions)以一种在线的方式连起(join)起来。所以系统被称为online data joiner。label标注
首先设定一个足够长的阈值。一个广告展示给用户之后,如果用户在阈值的时间内没有点击广告就标记为no-click,点击了的话就标记为click。这个等待的时间窗口需要非常小心的调整。
如果太长了,会增加缓存impression的内存消耗,而且影响实时数据的产生;如果太短了则会导致丢失一部分的点击样本,会影响click converage 点击覆盖。
click converage 点击覆盖表示有多少个点击行为被记录了下来生成了样本。online data joiner必须保证尽可能高的点击覆盖,也就是尽可能多的来记录下来所有的点击行为。但是如果等待太久就会增加缓存开销等影响。所以online data joiner必须在click converage和资源消耗之间做出平衡模型架构
处理大量的训练数据
很多的计算广告领域的训练数据量都是非常巨大的,那么如何有效的控制训练带来的开销就非常重要。常用的办法是采样均匀采样
均匀采样非常的简单,易于实现。而且使用均匀采样没有改变训练数据的分布,所以模型不需要修改就可以直接应用于测试数据。
不同采样率对模型性能的影响: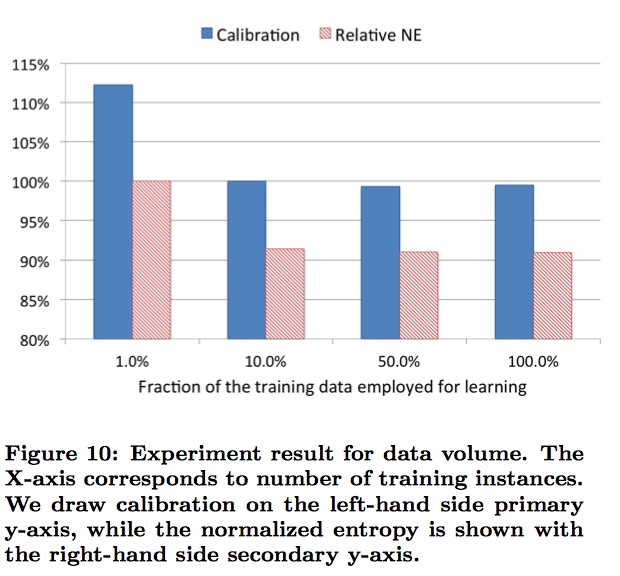
Negative down sampling
计算广告中大部分的训练样本都极度不平衡,这对模型会造成很大影响。一种解决办法就是对负样本进行欠采样。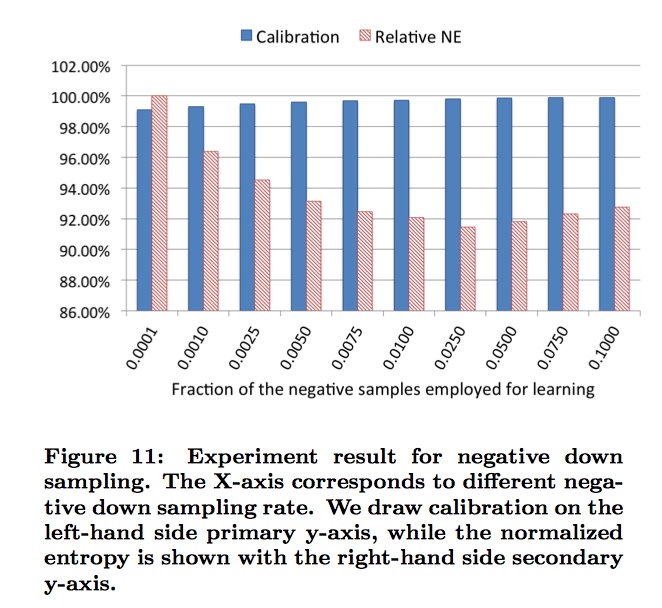
可以看到采样率不同,对模型性能影响很大。采样率为0.025的时候取得最好结果。
Model Re-Calibration
负样本欠采样可以加快训练速度并提升模型性能。但是同样带来了问题:改变了训练数据分布。所以需要进行校准。
举例来说,采样之前CTR均值为0.1%,使用0.01采样之后,CTR均值变为10%。我们需要对模型进行Calibration(校准)使得模型在实际预测的时候恢复成0.1%。调整公式如下: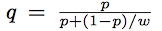
其中w是采样率,p是在采样后空间中给出的CTR预估值,计算得到的q就是修正后的结果。
其他实验结果
所有的这些探索都是为了能够平衡模型性能(accuracy)和资源消耗(内存、CPU)。只有当你充分了解模型和数据每个部分后,才能根据实际情况做出最佳的取舍。
Number of boosting trees
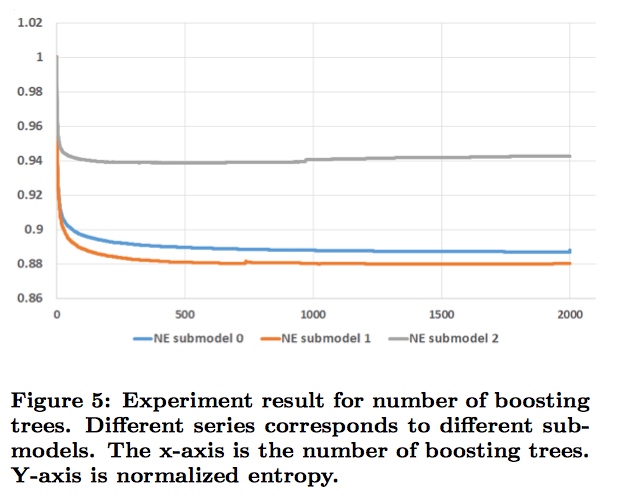
boosting tree数量从1到2000,叶节点个数被限制为最大12个。submodel之间的区别在于训练数据大小的不同,比如submodel 2的训练数据只有前面两个的1/4。
可以看到随着boosting tree数量的增加,模型的性能有所提升。但是几乎所有的提升都来自于前500个trees,而后面的1000个trees的提升甚至都不到0.1%。submodel 2在1000颗trees甚至模型效果在变差,原因是过拟合。
Boosting feature importance
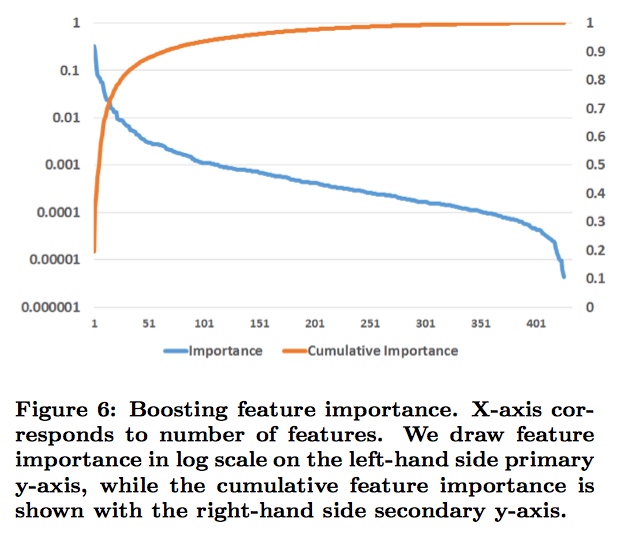
上图首先对特征按照重要程度来进行排序,编号后再画图。特征重要程度按照使用该特征进行分裂,所带来的loss减小的累积量。因为一个特征可以在多颗树上进行使用,所以累积要在所有的树上进行。
上图中,黄线表示对特征进行累加后的值,然后进行log变换。可以看到最终结果是1,表示所有特征的重要度总和是1. 最重要的是期初非常陡峭,上升的非常快,说明特征重要度主要集中在top10这些特征中。前10个特征,贡献了50%的重要度,后面300个特征,贡献了1%的重要度。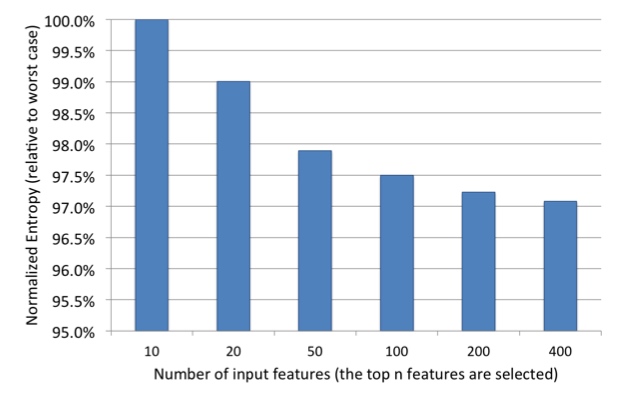
显然,全部去掉是不行的。说明大量弱特征的累积也是很重要的,但是去掉部分不那么重要的特征,对模型的影响比较小,比如从400到200。
Historical features VS Context features
针对两大类特征:历史信息特征(用户+广告)、上下文特征。论文还研究了这两类特征对模型性能的贡献程度。先给出结论:历史信息特征占主导地位。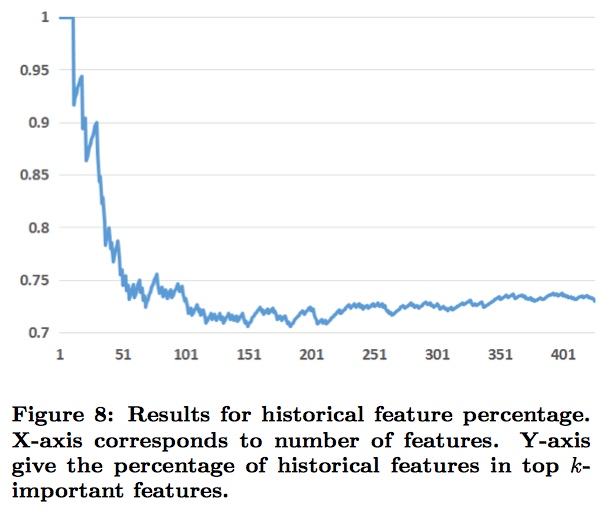
同样,先把特征按照重要程度排序,再画图。横轴是特征数量,纵轴是historical特征在top k个重要特征中所占的百分比。可以看到前10个特征中,全是历史信息特征;前20个特征中,只有2个上下文特征。所以:历史信息特征比上下文特征重要太多了。
总结
Facebook提出的LR + GBDT来提取非线性特征进行特征组合的方式非常经典,主要特性总结如下:
- Data Freshness很重要。模型至少一天需要重新训练一次
- 使用Boosted Decision Tree进行特征转换很大程度上提高了模型的性能
- 最好的在线学习方法:LR + per-coordinate learning rate
关于平衡计算开销和模型性能所采用的技巧:
- 调整Boosted decision trees数量
- 去掉部分重要性低的特征,对模型的影响比较小。但是不能全去掉
- 相比于上下文特征,用户/广告历史特征要重要的多
- 针对大量训练数据可以进行欠采样